5. 머신러닝 예측 모델 (회귀) (지하철 혼잡도 예측)
이전 글에서 이번 글까지 다른 글을 쓰느라 공백이 좀 길었다.
지금 쓰는 글은 2023.09.03~2023.09.26 에 진행했던 지하철 혼잡도 예측 및 분산 서비스 프로젝트이다.
https://mizima-data.tistory.com/16
4. 최종혼잡도 계산
혼잡도를 예측하기 위한 머신러닝 예측 모델을 만들기 위해, 앞에서 유의미한 변수라고 판단한 변수들을 포함한 최종 혼잡도를 구할 것이다. 1. 월별 요일별 비율 구하기 기존 혼잡데이터에선
mizima-data.tistory.com
이전 글에서 최종혼잡도 계산을 했다.
가공한 혼잡도 데이터를 머신러닝을 이용해 예측 모델을 만들어 보자.
현제 데이터는 최종혼잡도를 1호선부터 8호선까지 호선별로 나뉘어 있다.
데이터를 불러오자
import pandas as pd
df = pd.read_csv("8호선.csv")
sklearn을 이용해 데이터를 독립변수와 종속 변수로 나누고, 이를 학습 데이터와 테스트 데이터로 다시 나눈다.
from sklearn.model_selection import train_test_split
# 데이터를 독립변수(X)와 종속변수(y)로 나눕니다.
X = df[['YEAR', 'MONTH', 'DAY', 'STATION', 'DIRECTION', 'TIME_00']]
y = df['CONGESTION']
# 데이터를 학습, 테스트 데이터로 나눕니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)(이번 프로젝트에서는 train과 test 비율을 7:3으로 나누는 것이 정확도가 높게 나와 test_size를 0.3으로 진행했다.)
원핫인코딩(OneHot incoding) 적용
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# 범주형 열에 OneHot 인코딩을 적용
categorical_features = ['YEAR', 'MONTH', 'DAY', 'STATION', 'DIRECTION', 'TIME_00']
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(handle_unknown='infrequent_if_exist', sparse_output=False))
])
preprocessor = ColumnTransformer(
transformers=[
('cat', categorical_transformer, categorical_features)],
remainder='passthrough') # 나머지 변수를 유지
사용할 regressor를 불러온다.
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
from xgboost import XGBRegressor
- 처음엔 pipeline으로 RandomForestRegressor, LinearRegression, LGBMRegressor, XGBRegressor를 모두 실행해 보았다.
- 그 결과 평과지표와 피처중요도를 확인했을 때 XGBRegressor가 가장 합리적이라고 판단했다.
- 또 서비스 적용시 학습이 완료된 모델을 pkl 파일로 저장해 사용하는점,
- 위험예측모델을 만든다는 점에서 학습시간과 관계없이 성능이 좋은 모델을 사용하기로 결정했다.
모델 정의 (원하는 다른 Regressor 추가 가능)
# 모델 정의
models = {
"XGB_reg": XGBRegressor(random_state=42)
}
파이프라인 정의
# 파이프라인 정의
pipelines = {}
for model_name, model in models.items():
pipeline = Pipeline([
('preprocessor', preprocessor), # ColumnTransformer를 적용
(model_name, model) # 각 모델 적용
])
pipelines[model_name] = pipeline
파라미터 범위 정의 (Regressor 마다 따로 지정)
# 튜닝할 하이퍼파라미터 그리드 정의
param_dists = {
'XGB_reg': {
'XGB_reg__learning_rate': [0.01, 0.05, 0.1, 0.3, 0.5],
'XGB_reg__n_estimators': [50, 100, 150, 200, 250],
'XGB_reg__max_depth': [3, 4, 5, 6, 7, 8],
'XGB_reg__subsample': [0.5, 0.6, 0.7, 0.8, 0.9],
'XGB_reg__colsample_bytree': [0.5, 0.7, 0.8, 0.9, 1],
'XGB_reg__gamma': [0, 0.1, 0.2, 0.3, 0.4]
}
}
RandomizedSearchCV 진행
import warnings
from sklearn.model_selection import RandomizedSearchCV
warnings.filterwarnings('ignore')
# 모델 선택 및 RandomizedSearchCV 객체 생성
results = {}
for model_name, pipeline in pipelines.items():
param_dist = param_dists[model_name]
random_search = RandomizedSearchCV(estimator=pipeline, param_distributions=param_dist, n_iter=20, cv=5,
scoring='neg_mean_squared_error', verbose=2, n_jobs=-1, random_state=42,
return_train_score=True, refit=True)
random_search.fit(X_train, y_train)
results[model_name] = random_search처음에는 GridSearchCV로도 진행했으나 시간이 너무 오래 걸리고 RandomizedSearchCV와 결과에 큰 차이가 없이 나온다. 그 이유 때문인지, 웬만해선 GridSearchCV보다 RandomizedSearchCV를 많이 사용한다고 한다.
RandomizedSearchCV를 통해 나온 최적의 파라미터를 이용해 모델 생성 후 joblib을 이용해 pkl 파일로 저장한다.
(pkl 파일의 이름에 num8 (8호선) 이렇게 숫자를 붙여 호선별로 저장했다.)
pkl 파일로 저장시 학습이 완료된 상태로 모델이 저장되어 예측을 시도할 때마다 다시 학습을 하는 과정이 생략된다.
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import joblib
# 각 모델별로 최적 모델 및 하이퍼파라미터 출력, 최적 모델 저장
for model_name, result in results.items():
best_model = result.best_estimator_
best_params = result.best_params_
print(f"모델: {model_name}")
print(f"최적 하이퍼파라미터: {best_params}")
# 최적 모델 저장
joblib.dump(best_model, f'{model_name}_num8.pkl')
# 테스트 데이터를 사용하여 모델의 성능을 평가합니다.
y_test_pred = best_model.predict(X_test)
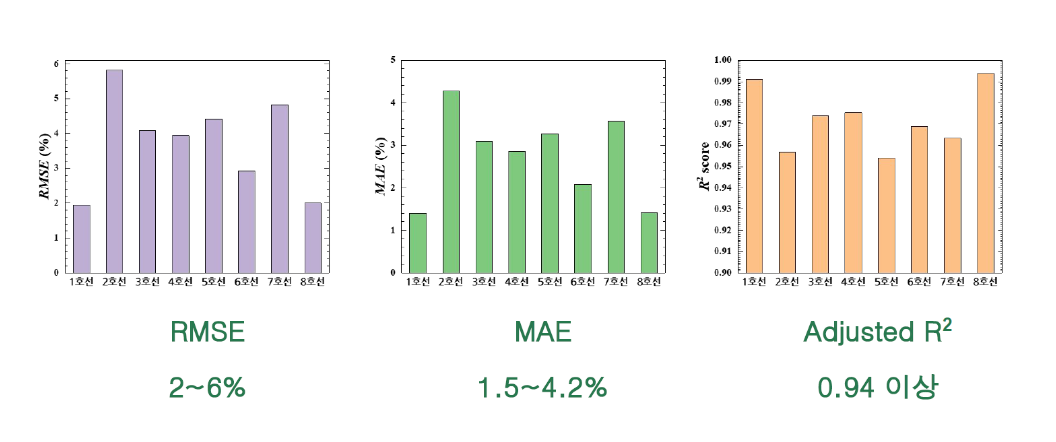
# MAE, RMSE, Adjusted R2 Score 계산
mae_test = mean_absolute_error(y_test, y_test_pred)
rmse_test = mean_squared_error(y_test, y_test_pred, squared=False)
n = X_test.shape[0]
p = X_test.shape[1]
r2_test = r2_score(y_test, y_test_pred)
adjusted_r2_test = 1 - (1 - r2_test) * (n - 1) / (n - p - 1)
# 결과를 출력합니다.
print("\nTest 성능 지표:")
print("Mean Absolute Error (MAE):", mae_test)
print("Root Mean Squared Error (RMSE):", rmse_test)
print("Adjusted R-squared (Adjusted R2):", adjusted_r2_test)
print('\n\n')(현재 아래 코드에는 최적의 모델을 출력하는 코드도 있는데, 여기까지 오는 과정에서 XGBoost 이외의 다른 Regressor를 추가로 파이프라인에 정의하고 진행했다면 좀 더 최적의 Regressor모델이 나온다.)

혼잡도 예측 예시
import pandas as pd
import joblib
def predict(pkl, X_data):
model = joblib.load(pkl)
# 예측을 수행합니다.
predicted_congestion = model.predict(new_data)
# 예측 결과를 출력합니다.
print("예측 혼잡도:", predicted_congestion)# 예측할 데이터 예시
new_data = pd.DataFrame({'YEAR': [2023, 2023], 'MONTH': [3, 10], 'DAY': ['월', '금'], 'STATION': ['서울역', '동대문'], 'DIRECTION': ['상선', '하선'], 'TIME_00': ['TIME_09', 'TIME_18']})predict('XGB_reg_num1.pkl', new_data)
